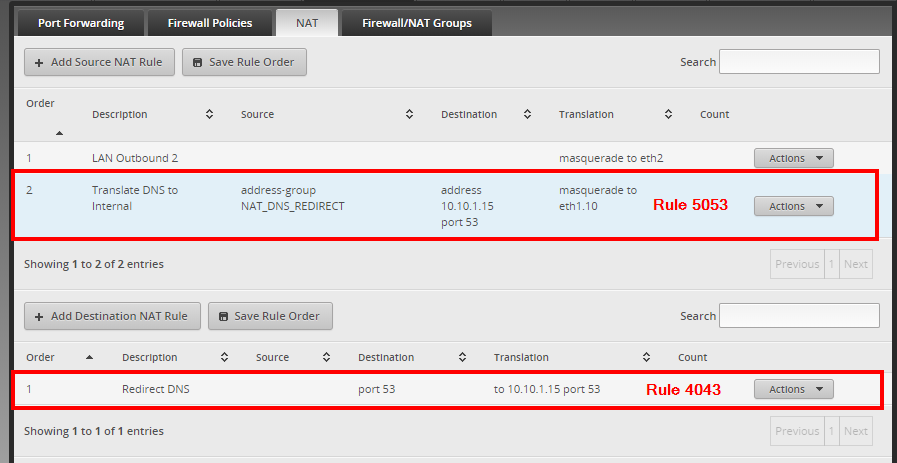
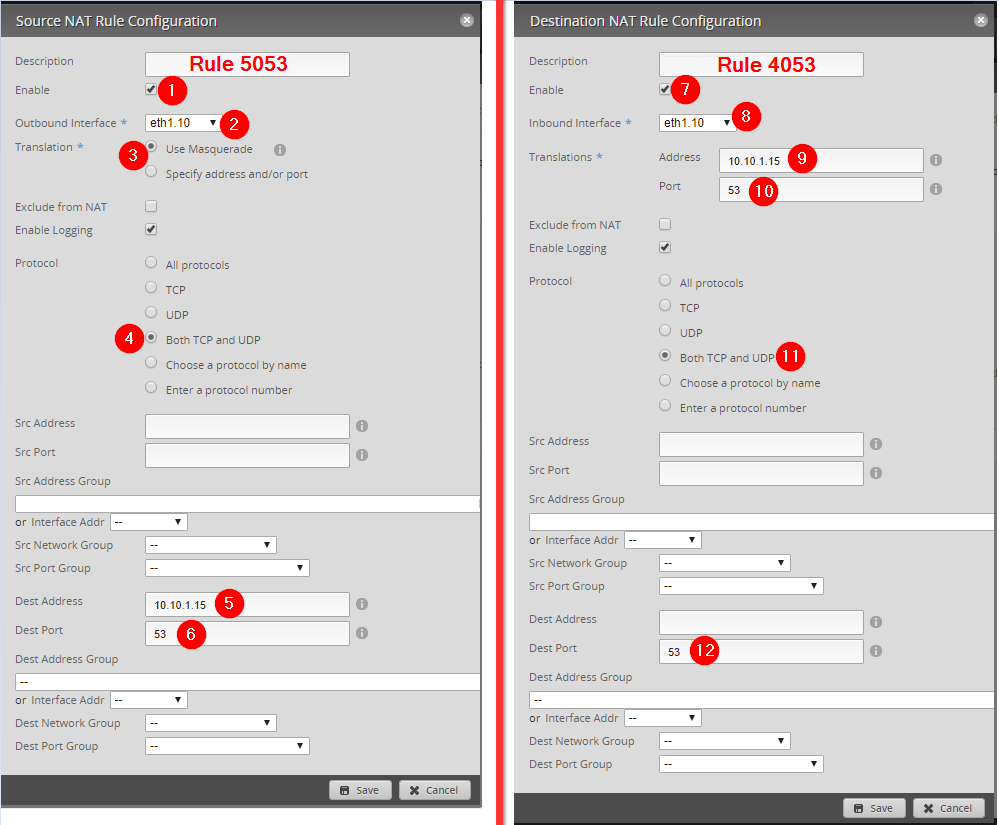
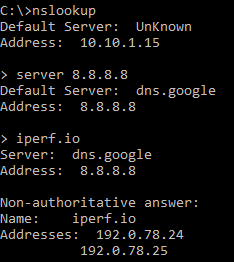
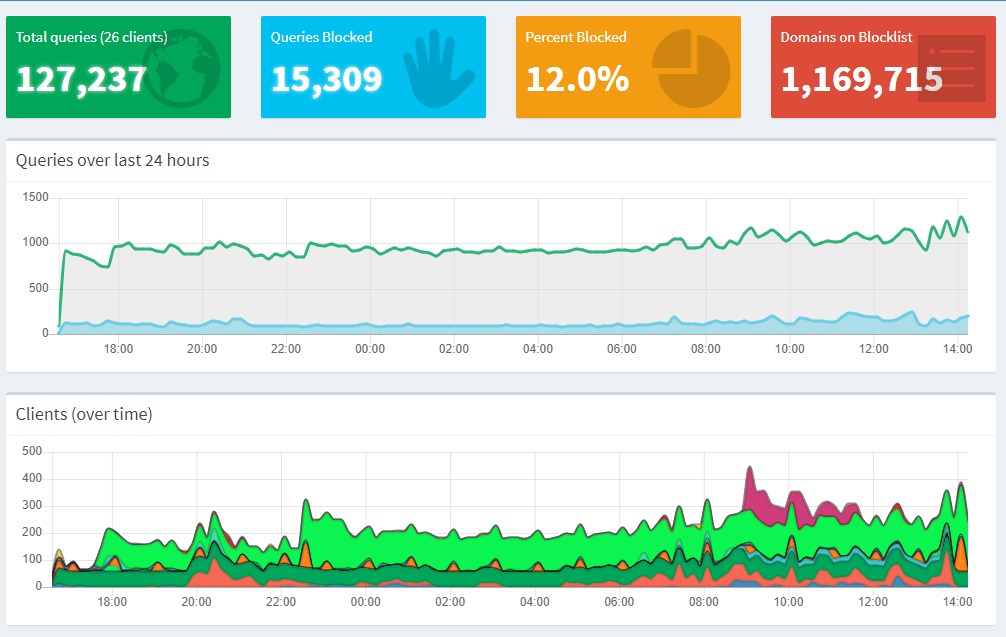
**Update** June 2020
In May 2020, the Blink Team sent an email indicating that the scripts leveraged in this blog post/GitHub are using an outdated method for authentication. I have confirmed that the as-implemented method is no longer functional. If time permits or demand is high enough, I will work on incorporating functional changes.

Backstory
For years, I fought with the idea of getting security cameras for the exterior of my residence, straddling between “I want all control and no monthly costs” vs. “I want some of the next-gen features and iterative software improvements” vs. “I care about my privacy too much,” among other considerations. If you are like me, you sought a camera system that didn’t require power cables, was wireless, and didn’t have a mandatory cloud storage subscription attached to it. I had come to my senses last year and realized that a cost-effective solution that is low-touch and has relevant features left few options to consider. After a decent deal on Prime Day this last year, I decided to get a three-camera, Blink XT2 system. Amazon acquired Blink in late 2017 for approximately $90 Million, effectively pairing a cost-effective camera solution with a cloud and retail/distribution powerhouse. I speculate that some of the feature/function gaps are the result of a maturing acquisition and relatively new product offering.
Feature/Function + Caveats
The Good: The Blink ecosystem provides a cost-effective solution for video surveillance. We get anywhere between 2-3 months out of a set of Energizer Lithium batteries for each camera, and this is not with the default setting as some cameras are persisting more than ten seconds of video for a given event. Additionally, I have bumped up the clarity on the cameras as the battery life is already acceptable to us. Lastly, the settings and ability to configure/tune are relevant and not too complex to understand.
The Bad: There are a few minor annoyances like the cameras being busy when motion is detected or when the video is presumably being saved. The more prominent annoyance is the lack of a web interface or otherwise, to save multiple videos. Blink provides you with 7200 seconds of recording time instead of a hard limit, like 5 GB. This isn’t fantastic by any means and makes it difficult for high-churn setups to provide latent value, meaning, going back to 20 days prior and looking for a specific recording might not be realistic. In my usage scenario, 7200 seconds is approximately 1 GB of data, averaging just over 136 KB/second of recorded video; it is not an extreme amount of data from a storage perspective. In my case, with 3 cameras, I get slightly more than 1 week’s worth of storage.
The Solution (For Technical Folks)
Some months back, I looked for solutions that could persist the recordings on my local storage for later use. I found that someone had built the protocol scaffolding and done the dirty work of documenting an undocumented API. I forked the protocol code, added some comments, and a few other things and published on GitHub after that.
The code can be found here: https://github.com/Kentix/BlinkCameraArchive/blob/master/Blink_Video_Downloader_Specified_AuthToken.py
For my setup, I performed the following steps:
- Ensure you have Python installed, if not, Python can be easily installed here: https://www.python.org/downloads/
- Clone the repo from GitHub or just download that single .py file, Blink_Video_Downloader_Specified_AuthToken.py
- Once saved, modify the .py file to contain your username and password. I loosely recall an issue with specific characters in the password field so if you are getting weird errors and have special characters, maybe change the password and remove them

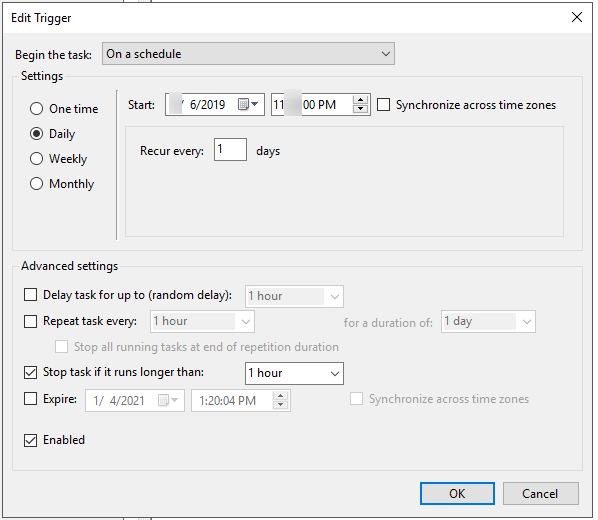
- At this point, you can run that file ad-hoc or you can make a scheduled task/cron job for this to run on a nightly basis. I have a scheduled task set up on a Windows system that runs every 24 hours.
Manual Run
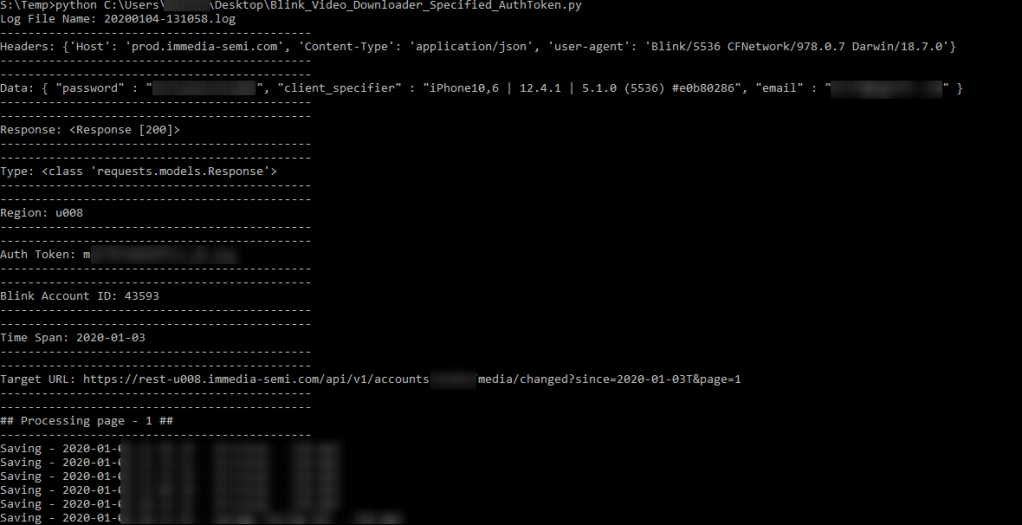
Below is an example of running it ad-hoc. The recordings (.mp4) will be stored in whichever directory you are running the .py file from, in my case, S:\Temp. Python is already in the PATH and is executable from any directory.
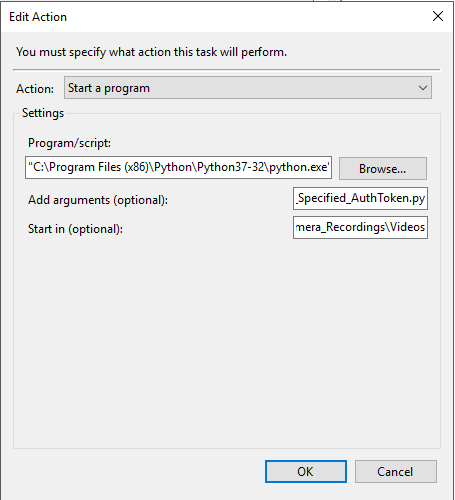
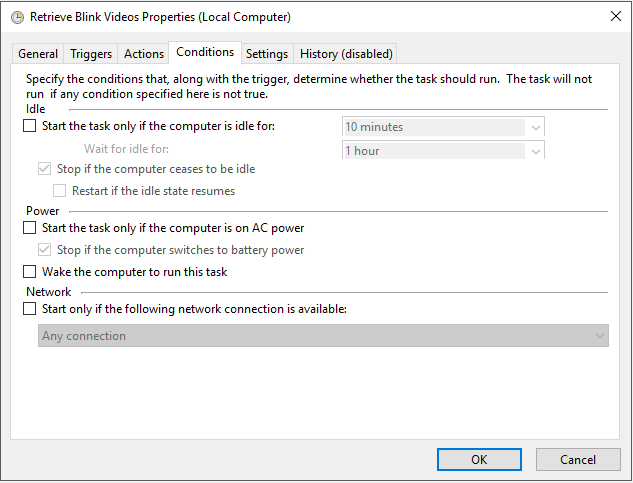
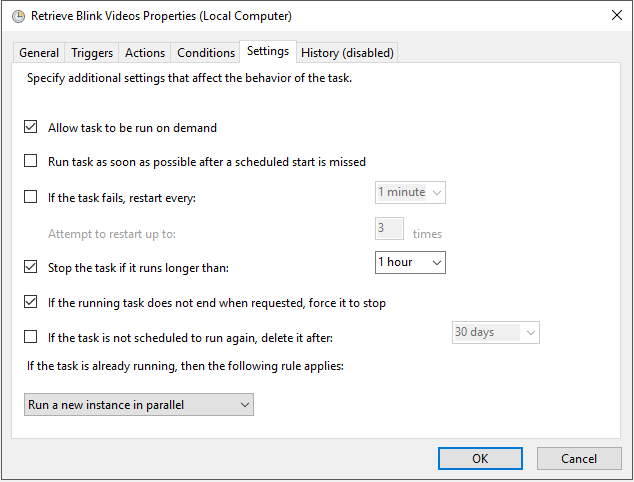
The Scheduled Task
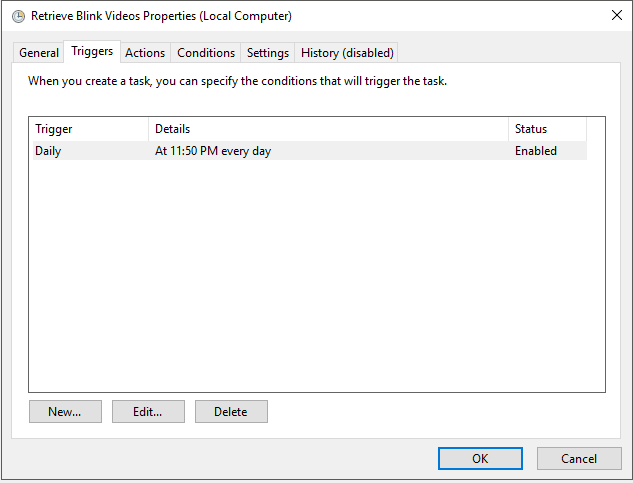
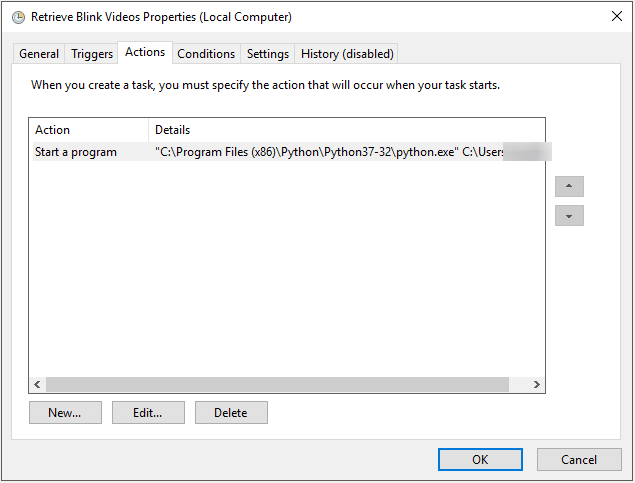
Adding a scheduled task is easy and is a consistent way in which you can retrieve the files without intervention. While I won’t go into detail, I will post some screenshots of how I have the scheduled task setup.

Manual Solution (Non-Technical, Awful)
If all of this is too complicated, an arduous failback is using the Blink mobile application to save the videos. As of this writing, you can do this one video at a time, and it will add it to your camera roll, at least on iOS devices.

Looking Forward
If there is decent traction on this post and others who want to do this with little to no technical knowledge, I may consider porting this over to a single executable that can be run with little to no expertise in the field. That said, if it becomes too prolific and causes Blink/Amazon angst, they will easily find ways to play cat and mouse and prevent this from happening at scale among their user base.
In the long term, hopefully Blink/Amazon build upon the ability to historically archive recorded assets.